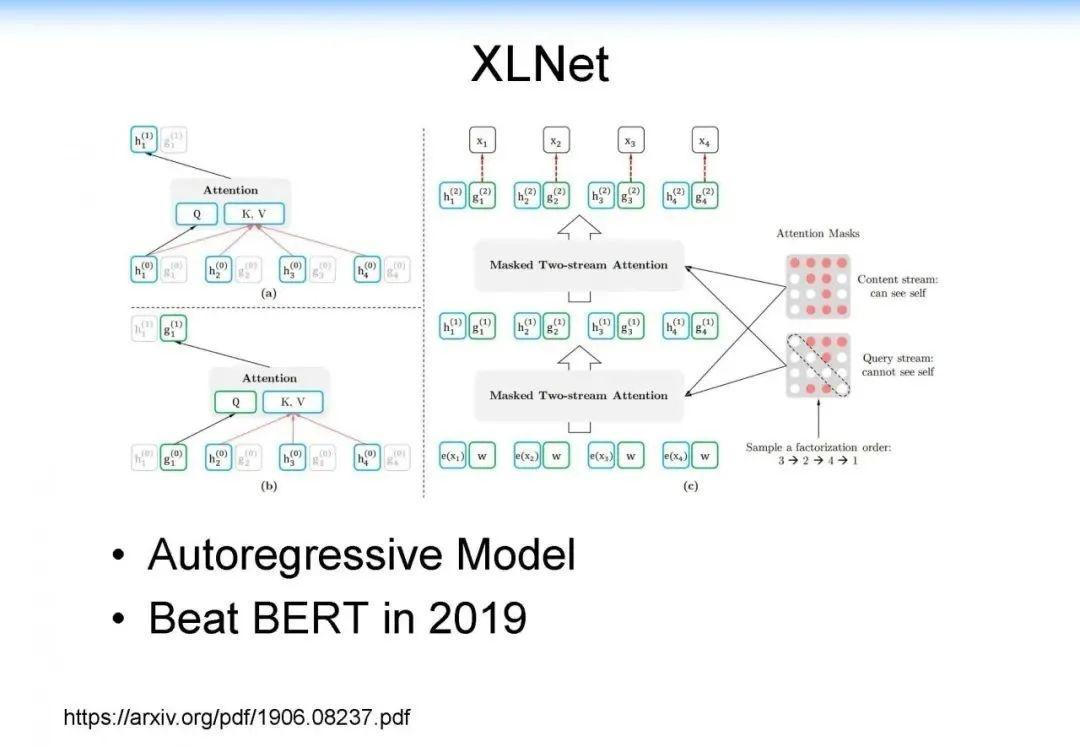
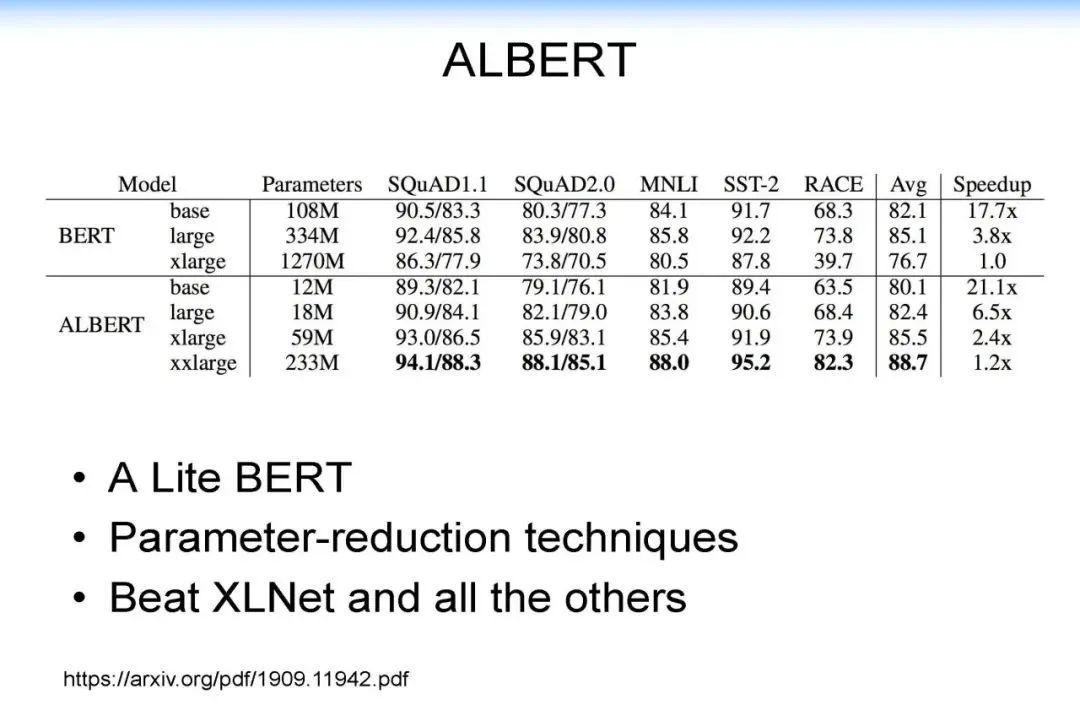
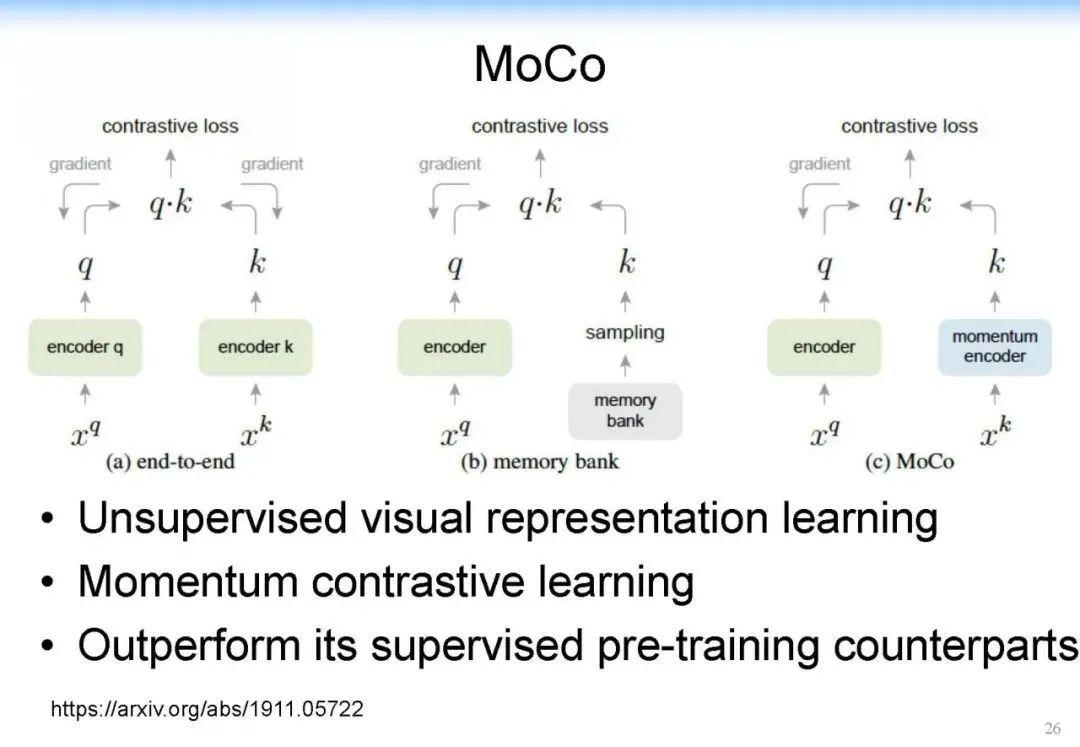
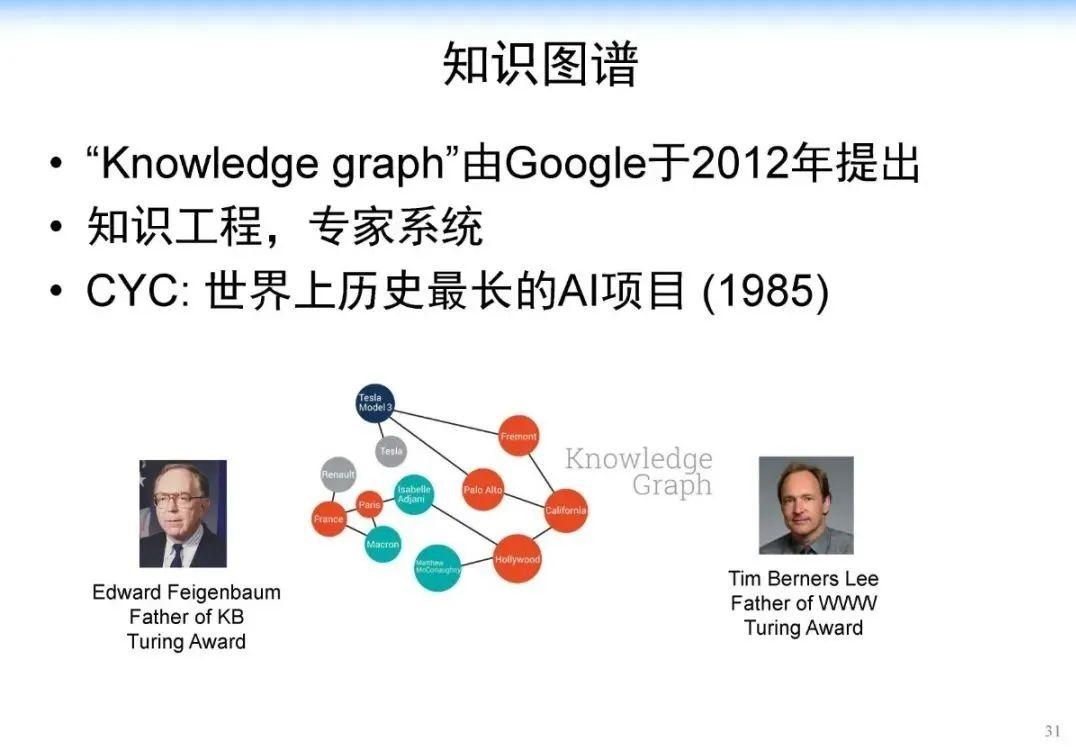
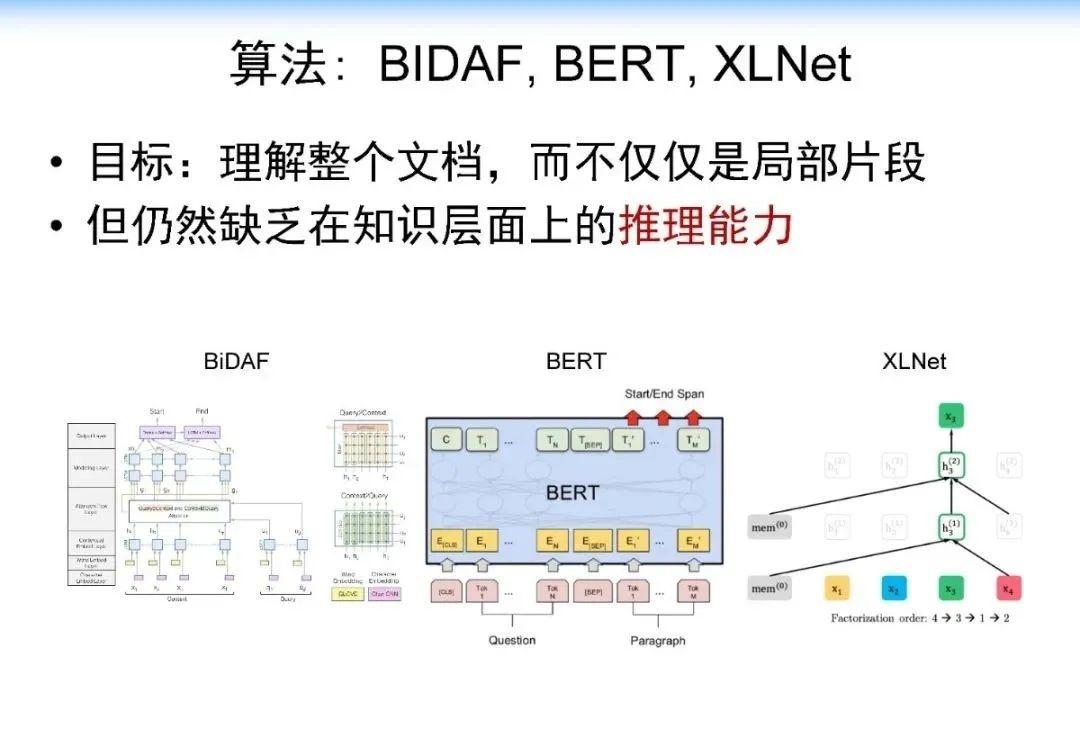
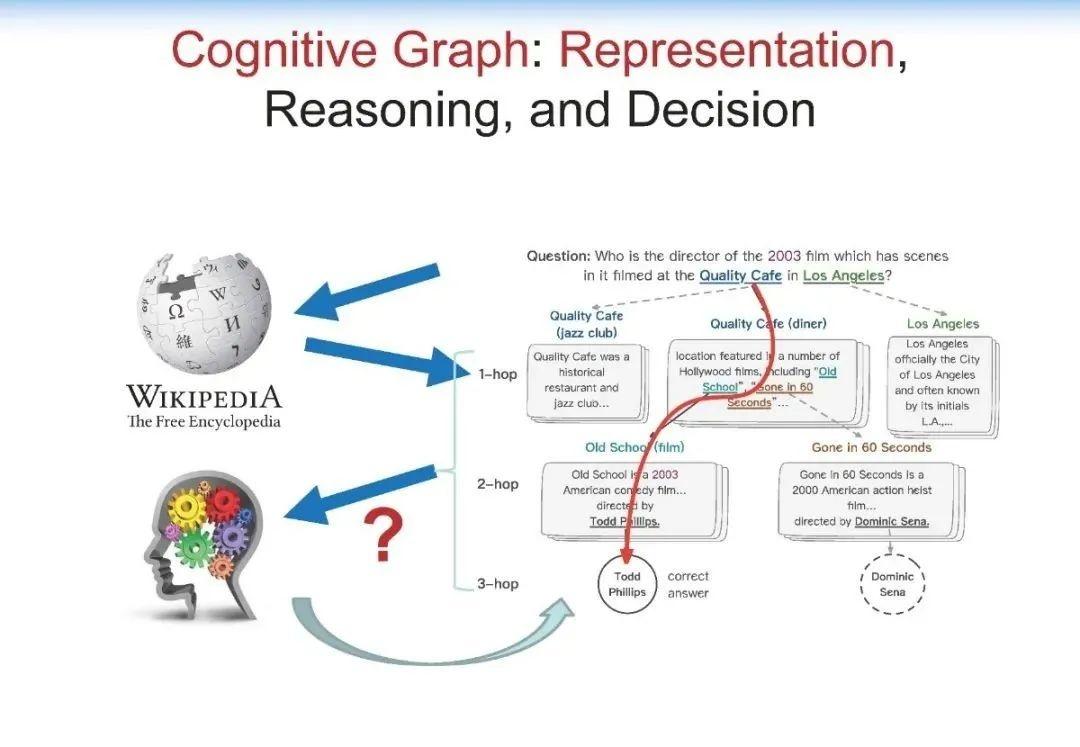
当我们用传统算法(如 BIDAF, BERT, XLNet)进行解决的时候,计算机可能只会找到局部的片段,仍然缺乏一个在知识层面上的推理能力,这是计算机很欠缺的。人在这方面具有优势,而计算机缺乏类似的能力。
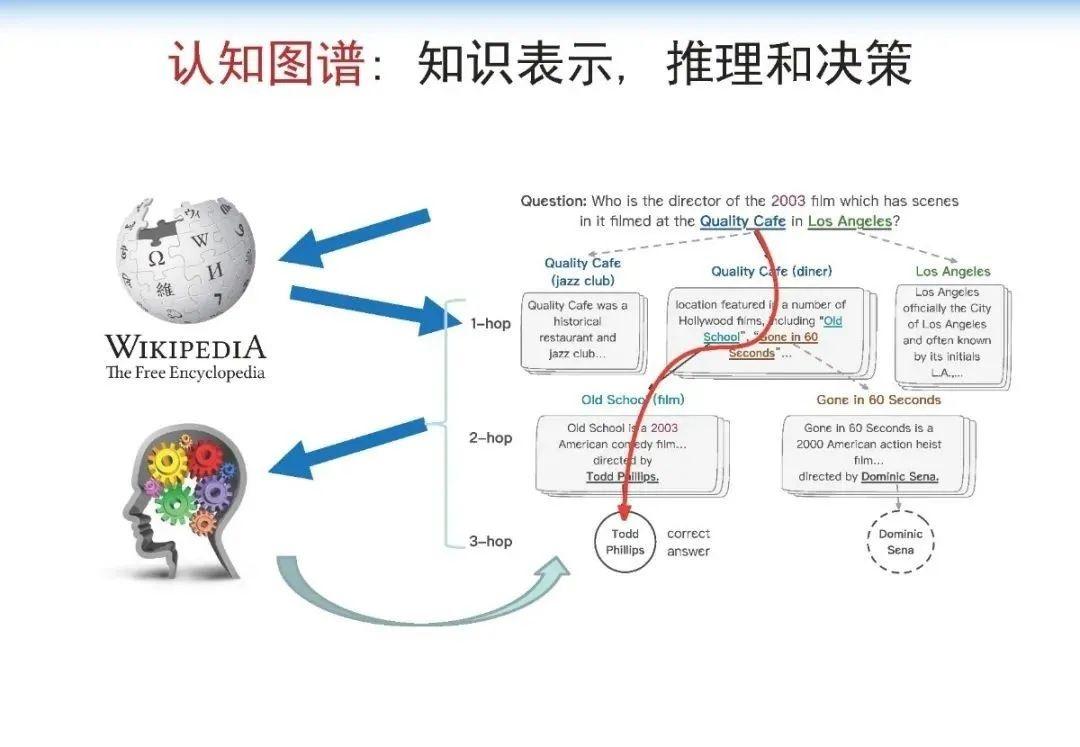
人在解决上述问题的过程中存在推理路径、推理节点,并且能理解整个过程,而 AI 系统,特别是在当下的 AI 系统中,深度学习算法将大部分这类问题都看作是一个黑盒子,如下图所示:
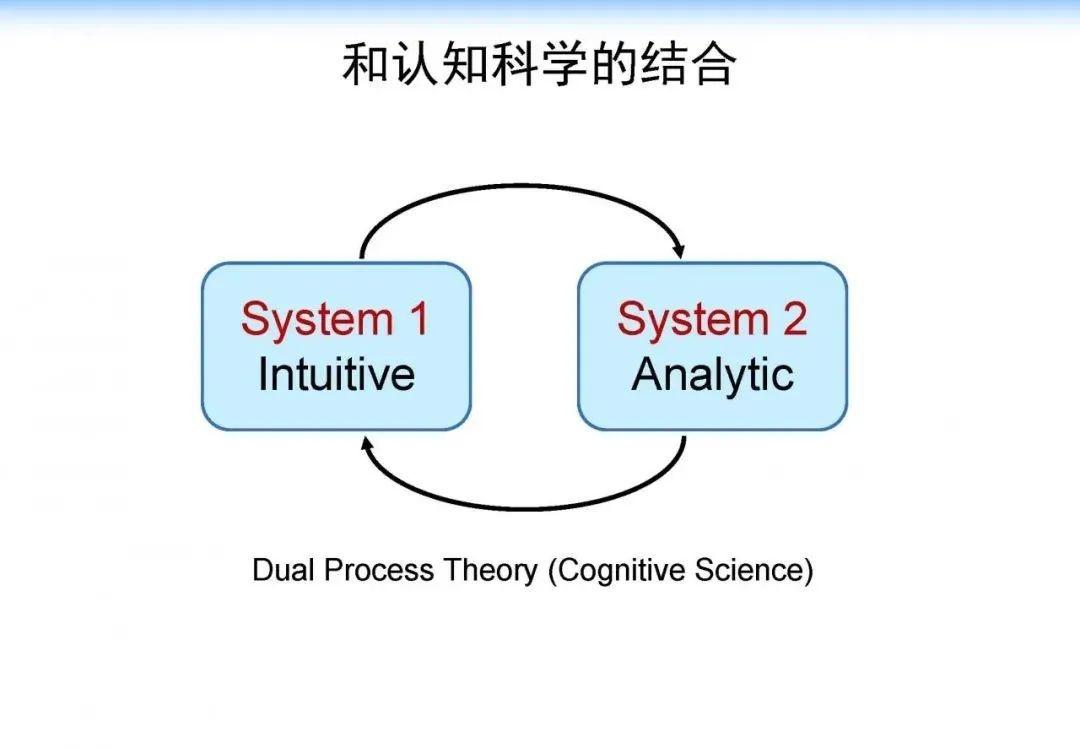
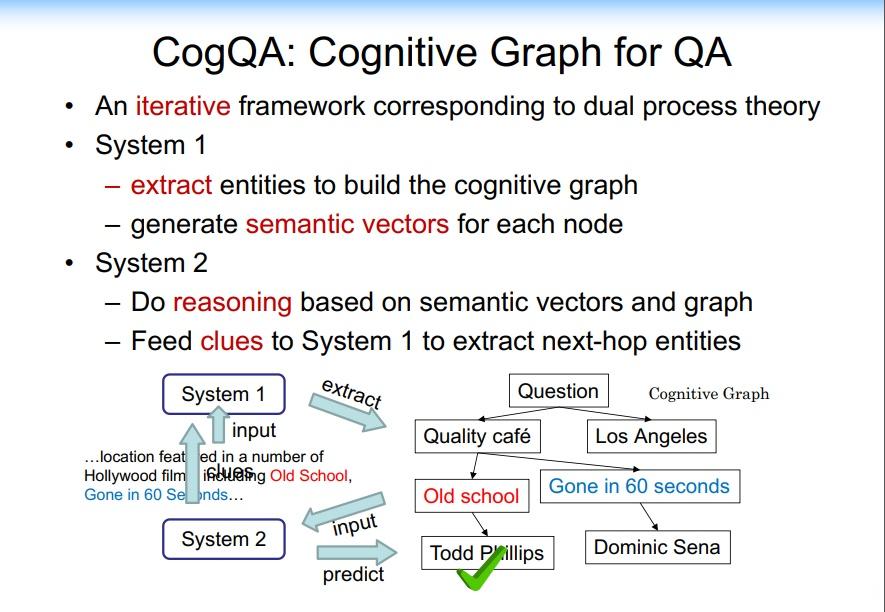
这个基本的思想是结合认知科学中的双通道理论。在人脑的认知系统中存在两个系统:System 1 和 System 2,如下图所示。System 1 是一个直觉系统,它可以通过人对相关信息的一个直觉匹配寻找答案,它是非常快速、简单的;而 System 2 是一个分析系统,它通过一定的推理、逻辑找到答案。
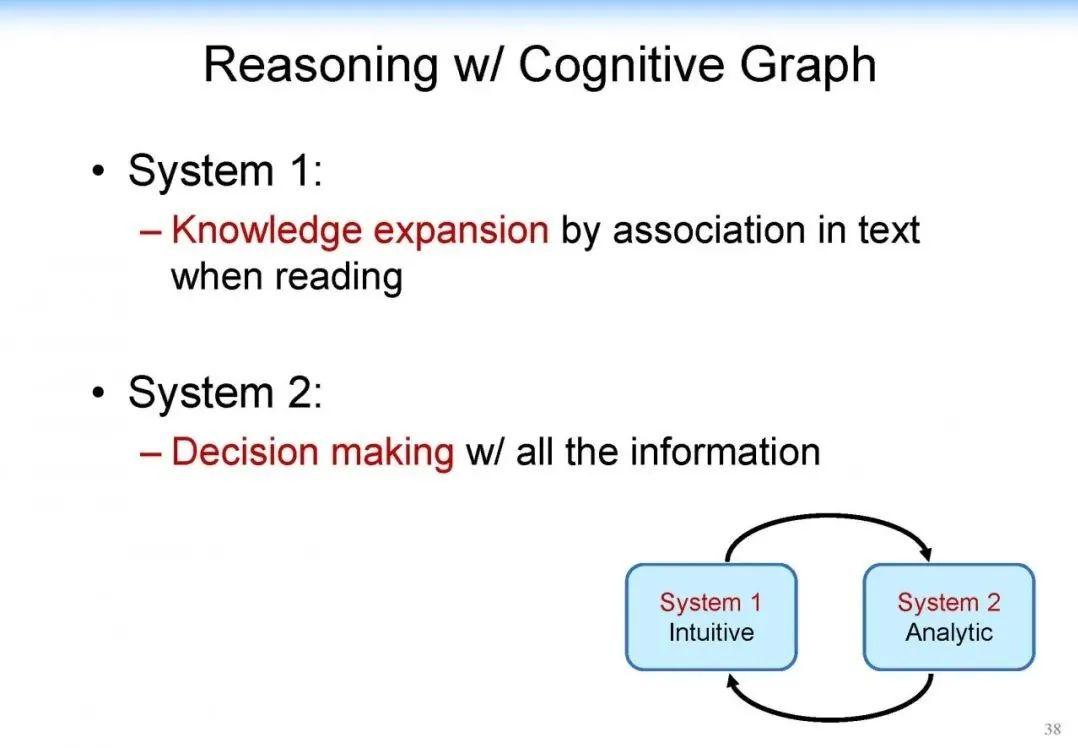
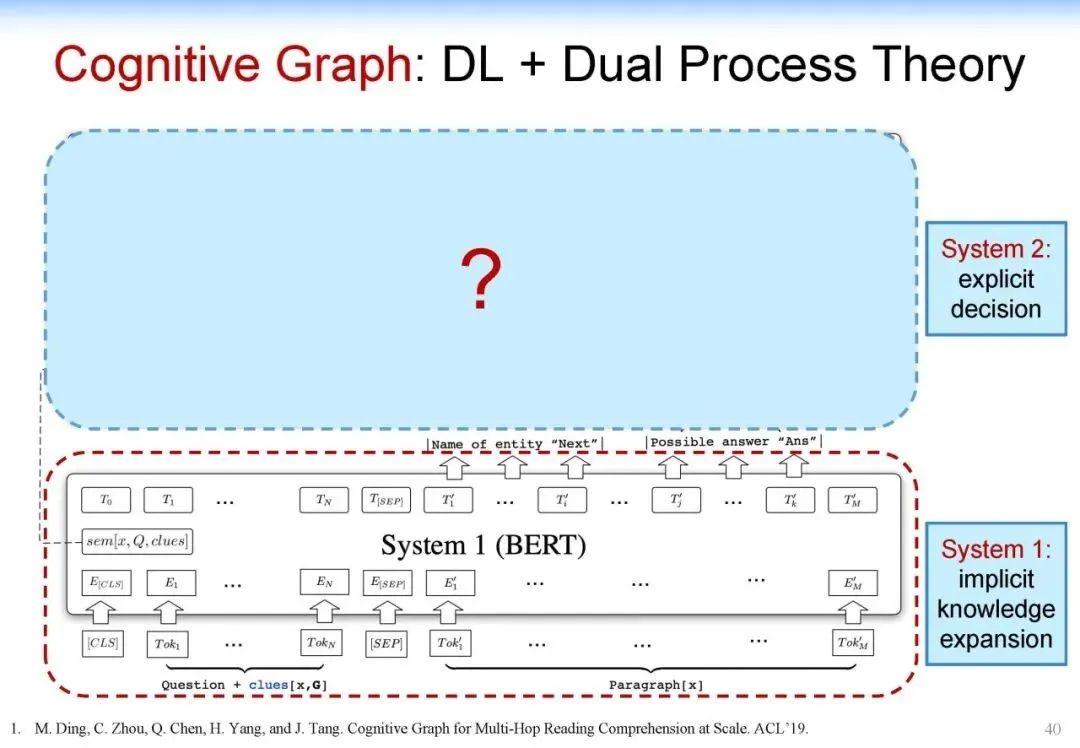
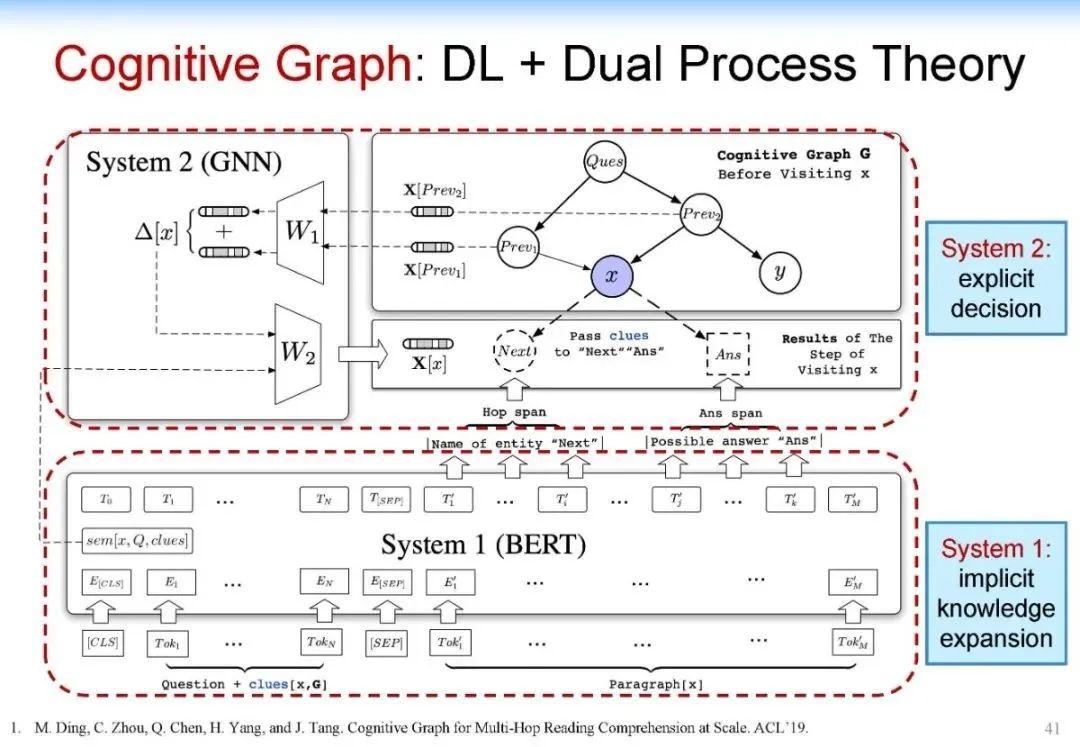
因此,我们大概用这个思路构建了这个新的、我们称为认知图谱的这样一个方法。在 System 1 中我们主要做知识的扩展,在 System 2 中我们做逻辑推理和决策,如下图所示:
可以看到,我们在 System 1 中做知识的扩展,比如说针对前面的问题,我们首先找到相关的影片,然后用 System 2 来做决策。如果是标准答案,就结束整个推理的过程。如果不是标准答案,而相应的信息又有用,我们就把它作为一个有用信息提供给 System 1,System 1 继续做知识的扩展,System 2 再来做决策,直到最终找到答案。



 发表于 2022-12-10 08:13:11
发表于 2022-12-10 08:13:11