|
|
2、时序法研究水文预测预报
接上文,水文时间序列数据数和量级勉强够用,本文演示用最朴素的水文要素构建简单的水文预报模型。把流量过程看作回归问题处理,模型采用滑动窗口和未来降雨作为输入,瞬时流量(和时段流量增量)为输出。要素只选择雨量(P)、流量(Q)。底层模型选择CatBoost,结构上采用多要素多目标方式。这是一个产汇流模型,偏产流,汇流过程叠加起涨流量。
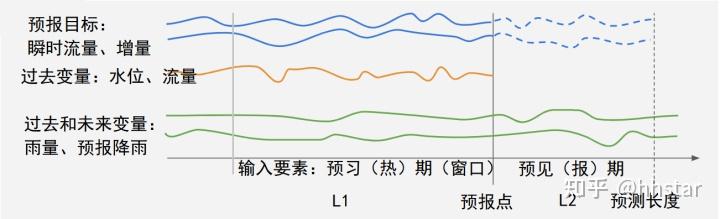
流域特性见下图,蓄满产流,天然坡道河流演进汇流。
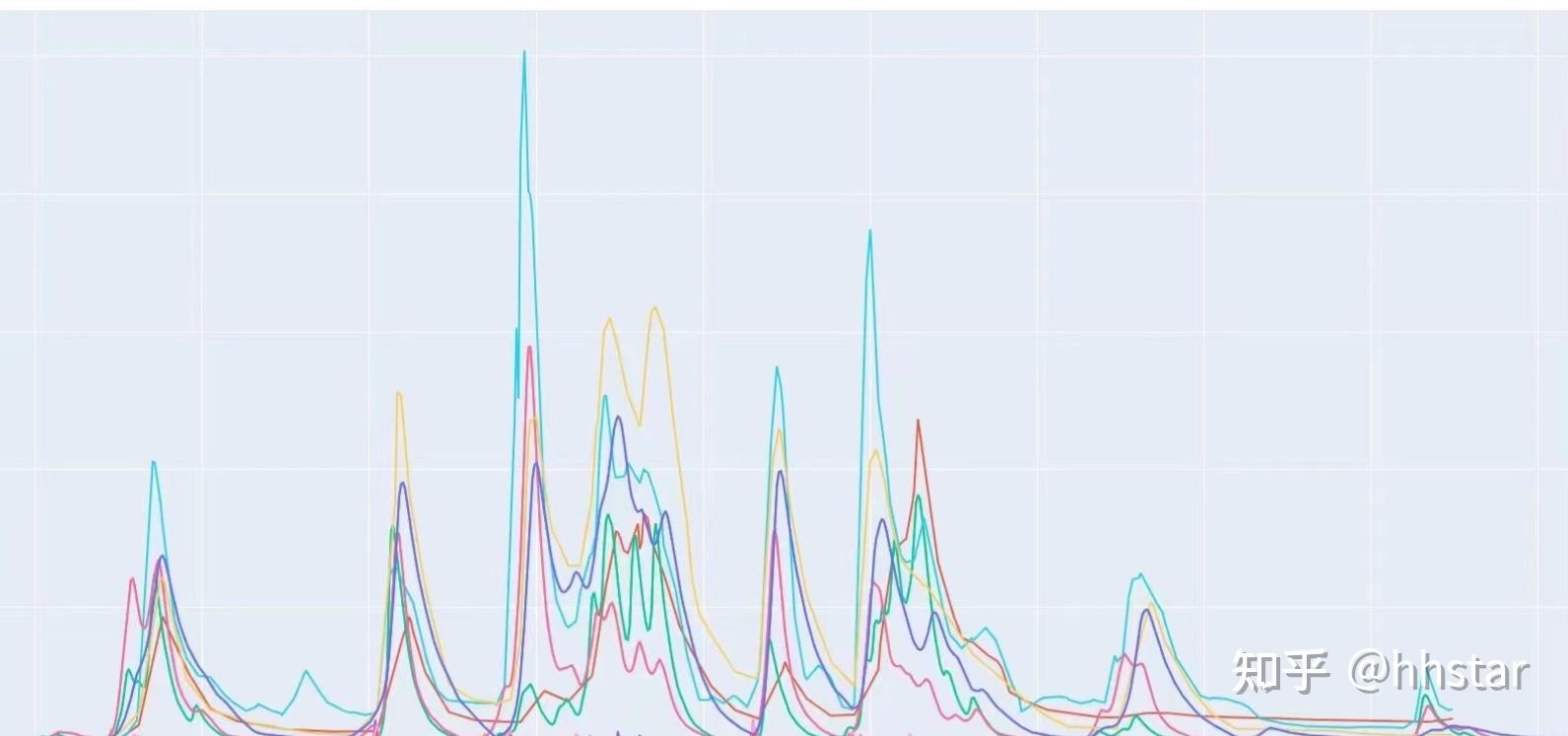
流量过程线
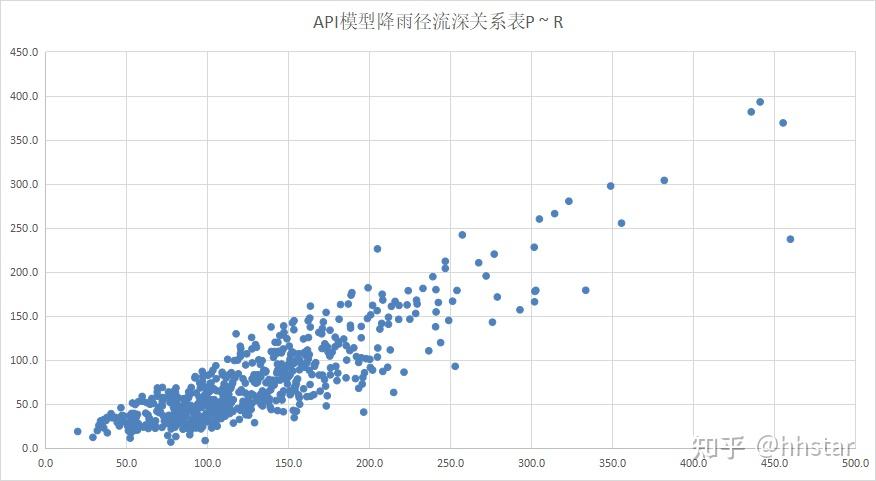
数据集流域特性:降雨径流深关系稳定;样本偏态分布
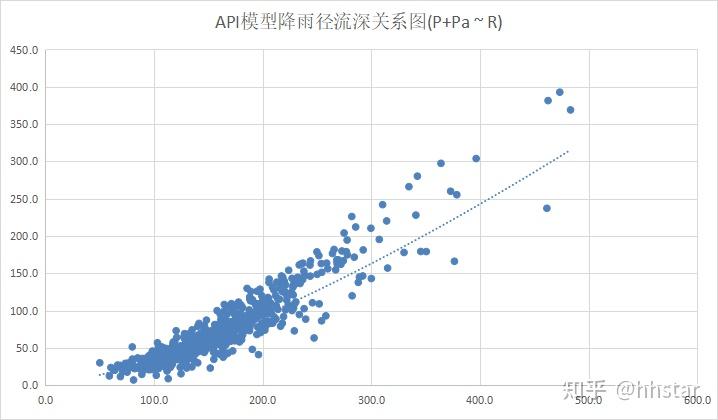
数据集流域特性:降雨+前期影响与径流深关系更紧密;高水部分发散,样本不均匀
- 数据集呈现非稳态,无明显季节性和趋势性;
- 降雨径流深关系稳定,样本偏态分布;
- 降雨(P)+前期影响雨量(Pa)与径流深(R)关系更紧密;
- 高水部分发散且样本少,分布不均匀;
- 中低水受Pa和下垫面影响较大;
- 饱和产流后,高水区域每毫米降水量产生的洪量(洪峰流量)趋于收敛,也就是中高水预报更具确定性。
- 饱和产流后,洪峰流量简单估算公式为:Q0 + 7 * P面 ,其中Q0在200 - 400之间。此后每1毫米面降雨量大约产生7立方米每秒的流量。
火星夏普山地表水水文控制站雨量流量时序脱敏演示数据集:15年2小时演示数据( 链接: https://pan.baidu.com/s/1nISlRw-HRAeupyv73vNQow 提取码: eehd )。
数据说明:
- 7个雨量站雨量数据,精度1毫米;
- 1个控制站流量,流量精度为10立方米每秒;
- 日面平均雨量,精度0.1毫米;
- 分辨率:2小时;
- 最后近2年数据删除流量数据,用于验证;
- 脱敏数据,没有地理信息,气象信息---“火星夏普山”。
更丰富的地表水水文控制站雨量流量时序数据集(气象数据集),请联系作者。
演示数据集只有十几年的序列,选择CatBoost为底层模型,包装为时序多目标多要素结构。同时,也尝试过TCN、TFT等深度学习模型,效果不理想。Python代码,采用32位精度,支持CPU和GPU运算。纯CPU平台也可以运行,慢慢腾腾。
2.1 水文要素时序数据集特点分析
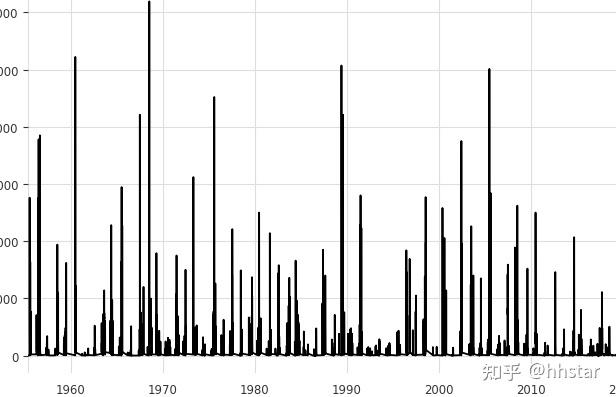
数据集呈现非稳态,无明显季节性,洪水过程主要受上游降雨(大、暴雨)影响,数据全部为0或正数
如图所示,演示数据集有以下特点:
- 洪水过程主要受上游降雨(大、暴雨)影响;
- 涨水早期过程已经体现流域下垫面状况;
- 汛期洪水过程基本完整,非汛期要素数据丢失严重;
- 流量过程连续发生,且无法归因分割。既然是时序流式数据,不能简单按照场次划分。每一刻流量是流域产流和汇流综合结果。模型采用滑动窗口输入变量。模型需要支持协变量;
- 各站点预习期和预见期长度不同。模型自适应不同控制站预见期;
- 同时支持过去变量(已经发生的变量)和未来变量;模型支持过去历史变量、未来变量,且连续支持;
- 多要素多目标,(概率支持);
- 前期影响雨量不是必须的。Pa为前期土壤含水量;K为系数,Im为流域最大蓄水容量,后文根据流域蒸发特性,确定Im值。后期修正干旱状况下Pa曲线,引入负数,并作为超参数优化微调参数。经资料分析验证,与API模型结论基本一致
- 数据全部为0或正数。
2.2 演示数据集模型选择
结合前文描述,模型选择的条件:
- 支持多要素多目标或者包装为多目标;
- 支持自动静态标签模型或者支持静态变量;
- 支持协变量;
- 支持过去、未来变量;
- (支持概率模型);
- 算力要求越多越好。
综上所述,演示模型选择开源的CatBoost作为底层模型。
CatBoost特点(摘录如下:)
CatBoost算法是gradient boosting算法中的一种,是继LightGBM之后基于GBDT改进的算法,由俄罗斯Yandex公司在2018年开源。相较于LightGBM算法,CatBoost算法有很多特点,但最引人注目的是对分类型特征的处理。这使得我们在训练模型之前可以考虑不用再通过特征工程去处理分类型特征预测偏移处理。这可以减少模型的过拟合,提升模型预测效果。本文算法只接受数值型数据输入。
实践表明,LightGBM波动更大,视野偏眼前,收敛慢,都容易过拟合。CatBoost视野更宽,对异常值容忍度更好,GPU加速效果更好,更容易收敛,缺点是偏时段量(雨量站特征比重大),对上下游相关和连续强降雨过程,偏降雨产流影响,汇流部分倚重不足,需要后期在汇流时加起涨流量(Q0)校正。模型偏产流轻汇流,严格来说是个产流模型。数据流程图见下图,时序模型输入输出,滑动窗口结构。
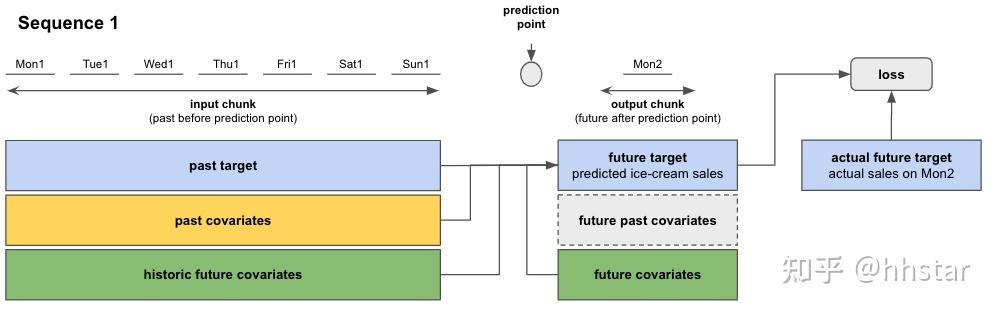
上图来源于网络
水文要素时序和输入输出滑动窗口示意图
2.3 演示数据集特征工程
2.3.1 峰现时长确定
模型输入为滑动窗口宽度内特征值,实例仅为雨量和流量,没错,含已经发生的流量过程。参考前文假设:早期过程已经体现流域下垫面状况,实际情况也是这样发生的,产流汇流是个统一的过程。
按照教科书定义,确定2个峰现时长(L2和L1),一个是主降雨结束至洪峰之间时长,一个是主降雨时段中值与洪峰之间时长。实践表明,简单算法也是有效的,pearson相关系数靠谱。不同场次洪水因流速变化而导致峰现时差,由模型来拟合。本文直接采用pandas.corr相关函数,参数默认'pearson',LCSS扫描,取最大值。不同分辨率下峰现时长基本一致。伪代码如下:
L2 = [int(np.argmax([(df[p].corr(df['Q'].shift(-hm))) for hm in range(72)])) + 1 for p in p_n_col]
- 代码中p_n_col为同一时段各雨量平均值,Q为流量。
- 通过计算,确定演示数据集L2为12-15小时,L1取L2的两倍以上,本文取24-36小时。
- 实际作业预报中,对于短历时暴雨洪水,一致的L1能取得更高的精度(主降雨历时相近,起涨流量另算),复式洪水取平均值即可。
- 峰现时长与API模型基本一致。
- 上下游控制站洪峰相位差,用同样的算法确定,后续特征工程时,滞后滑动,以适应高中低水不同流速的河道演进。
2.3.2 数据增强、数据集拆分和交叉验证
数据增强。本文时序频率为3小时,与提供的演示集是同一数据集,不同的统计口径。滑动采样,实现数据量翻倍。其中雨量为时段累积值,流量为瞬时流量(流量过程线波形外沿)。 模型并行处理这些数据,不是分段串行训练。
实践表明,演示数据集1小时、2小时分辨率对精度没有明显改善。故采用低耗能的3小时分辨率。
时序集的数据集拆分和交叉验证与普通数据集不同,不能跨界引入变量。演示数据集前n年为训练集,后两年为验证集。实际应用中,预报模型以2000年分界线,以前为训练集,以后为验证集。
关于交叉验证。由于数据集太短,只有区区几十场洪水,不使用切片后退式交叉验证。
2.3.3 数据归一化
采用sklearn工具包。这个过程不是必须的,已经习惯了,就做了。实践中除对方差特征一致性检查有用外,对模型精度没有明显影响。
from sklearn.preprocessing import MinMaxScaler , MaxAbsScaler
scaler = MinMaxScaler(feature_range=(0.1, 1)) #scaler = MaxAbsScaler()
transformer_Q, transformer_past_covariates(, transformer_future_covariates = Scaler(scaler), Scaler(scaler), Scaler(scaler)
ts_q_train = transformer_Q.fit_transform(train_Q)
ts_q_val = transformer_Q.transform(val_Q)
... 2.4 模型定义
CatBoost时序版模型有现成的轮子,拿来主义,忽略分位数概率预测,采用确定性模式。参数如下:
kwargs = {'task_type': 'GPU' if device.type == 'cuda' else "CPU"}
my_model = CatBoostModel(
lags = L1,
lags_past_covariates = L1,
lags_future_covariates = (0,L2),
output_chunk_length = L2,
# likelihood = 'quantile', # 概率
# quantiles = QUANTILES, # 分位数
**kwargs
)2.5 模型训练
模型支持测试集与训练集一并参与训练(数据量太少)。其中s 为目标变量Q,p为过去已经发生的变量P、Q,f为未来变量Q。
for t_s in [pd.Timestamp('200501010800')]: # 交叉验证列表
t_e = pd.Timestamp('201905010800')
s ,p ,f = [] , [] ,[]
v_s, v_p, v_f = [], [], []
for i in range(len(train_e_transformed)): # 3小时滑动采样并行训练
s.append(ts_q_train [t_s:t_e])
p.append(ts_train_past_covariates[t_s:t_e])
f.append(ts_train_future_covariates[t_s:t_e])
v_s.append(ts_q_val[t_e:])
v_p.append(ts_val_past_covariates[t_e:])
v_f.append(ts_val_future_covariates[t_e:])
my_model.fit(
series = s,
past_covariates = p,
future_covariates = f,
val_series = v_s if val else None,
val_past_covariates = v_p if val else None,
val_future_covariates = v_f if val else None,
)2.6 可解释性和超参数调优
可解释性和特征重要性。不解释还好,越解释越糊涂,好酒不怕多喝,重要的特征必须反复强调。
explainer = Explainer(my_model, ...)
explainer.plot_vsw(...)
expl_result = explainer.explain(my_series, my_past_covs, ...)
explanation = expl_result.get_explanation(component="my_target_dimension_of_interest", horizon=L2)超参数调优采用optuna算法。调优指标,选择smape。根据《水文情报预报规范》相关章节定义(参考2.8精度评定图),结合实际调参过程考证,QR,DC(CD)指标与smape指标趋势一致,故简化选择smape代表。实际预报方案采用多种指标评价体系,如:DC、 QR、ope、r2_score、 mse、 rmse、 smape、 nse、kge等。
def objective(trial: Trial) -> float:
param = {
'PaMn': trial.suggest_discrete_uniform('PaMn', -1.5, 1.2, 0.02), # 前期影响曲线分布修正
'l2': trial.suggest_int('l2', L2 - 1, L2 + 2, 1), # 预见期网格
'n_estimators': trial.suggest_int('n_estimators', 100, 400, 100) , # 次数,Catboost收敛快
'learning_rate': trial.suggest_discrete_uniform('learning_rate', 0.04, 0.2, 0.01) ,
}
...
return smape_val if smape_val != np.nan else float("inf")
study = optuna.create_study(direction='minimize')
study.optimize(lambda trial: objective(trial), n_trials= 300 , show_progress_bar = False , n_jobs= 2)
print('Best trial: score {},\nparams {}'.format(study.best_trial.value, study.best_trial.params))2.7 预测(或称预报、推理)
推理采用逐点推理法,即每个节点预见期最低L2时长。为提高推理时效,仅摘录洪峰流量大于阀值的洪水过程作预报。预报过程线采用1个滤波器平滑,再接一个宽度为L2的时序压缩算法减小波动。
2.8 精度评定

图片来源于网络
上图为《水文情报预报规范》精度评定简化表。峰值精度评定采用DTW窗口(L2-L1)滑动对齐原始流量过程和预报流量过程,侧重洪峰流量比对,更贴近API模型和传统预报方式。采用上述特征值的模型预测结果不理想。
CatBoost_3_24_12_Q_2:
ope >0.2,ope_90, CD,QR ,ope, ,QR2000, QR3000,r2_score, mse, rmse, smape, nse,kge, kgeprime
0.38432 0.3 0.66588 0.5 0.438 0.6 0.035029 0.88892 433.331162 20.816608 0.082415 0.71884 [0.82916 0.85049 0.91732 1.0005 ] [0.82893 0.85049 0.91686 1.0005 ]
究其原因,除数据偏少,代表性差外,没有构建水文特色的特征工程也是重要原因,后文将详细描述水文特色特征工程原理、算法和泛化能力。下列数据为实际应用模型精度指数情况,勉强为甲等方案。(CatBoost_3_36_12_Q_2)
ope>0.2,DC,QR ,ope, QR2000, QR3000,r2_score, mse, rmse, smape, nse,kge, kgeprime, kgenp
0.31373 0.86527 0.893 0.8 -1 0.05535 0.93571 100.3839 10.01917 0.128372 0.8747 [0.9265 0.9357 0.96439 0.99946] [0.92675 0.9357 0.96491 0.99946] [0.98908 0.98912 0.99922 0.99946]
2022-12-03
春种秋收,未完待续 |
|



 发表于 2022-12-11 16:54:18
发表于 2022-12-11 16:54:18